

Your LLM hallucinates, Why?

It is a fact that large language models (LLMs) have really made life easier for the whole world, and there has really been a huge adoption of AI in all areas of life. But as much as this new trend is interesting and helpful, it also has its limitations.
One of the limitations of LLM is “hallucination”, others include:
Contextual understanding
Domain-Specific Knowledge
Lack of Common Sense Reasoning
Continual learning constraints.
What does it really mean for an LLM to hallucinate?
Hallucination refers to instances where the model generates information or outputs that are factually incorrect, nonsensical, or not grounded in the provided context.
We can also say:
A hallucination occurs when the model generates text or responses that seem plausible on the surface but lack factual accuracy or logical consistency.

Things to consider if your model is hallucinating:
- Token Limit
The token limit is the maximum number of tokens or words, that the model can process in a single sequence. Tokens can include words, subwords, or characters, each represented as a unit in the model’s input.
This limit is imposed due to computational constraints and memory limitations within the model architecture. It affects both the input and output of the model. When the input text exceeds this limit, the model cannot process the entire sequence at once, potentially leading to truncation, where only a portion of the input is considered. Similarly, for text generation tasks, the output length is also capped by this token limit.
The token window limit is how many words an LLM can absorb while generating an answer. Your LLM (e.g. ChatGPT) is a sponge — what does this mean?
Too much much water (words) = no more absorption.
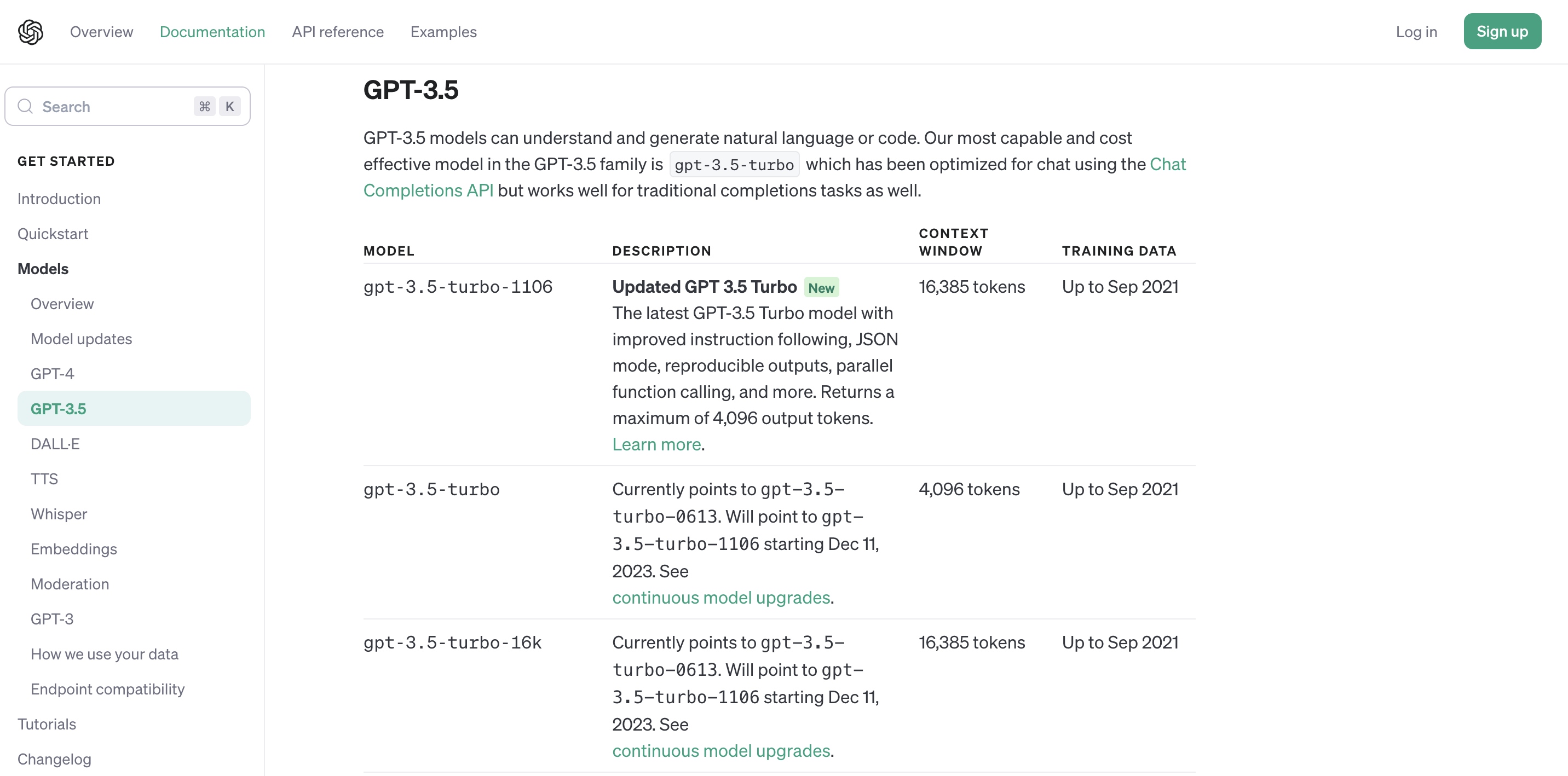
GPT — 3has a limit of 2048 tokens (gpt-3.5-turbo has up 16,385 tokens).GPT—4has a token limit of 128,000 tokens.
For instance, if an LLM has a token limit of 2048 tokens, any input longer than that would need to be split into smaller segments for processing, potentially affecting the context and coherence of the information being processed.
This token limit poses challenges when dealing with lengthy texts, complex documents, or tasks that require processing a large amount of information in a single sequence and this can lead to model hallucinations.
- Token isn’t everything
Claude 2.1 now has a 200,000 token limit and you might think it must be the best LLM yet. Well, not really. An academic paper shows the opposite, they tested Cluade 2.1 and GPT-4. They performed a “needle in a haystack” scenario and both LLM had to find the information. The longer the text, the harder. Makes sense?
The study also shows other factors:
How attentive to details the LLM is.
It’s ability to discern relevance.
So bigger does not necessarily mean better, it challenges the notion that a larger token limit in LLMs = better performance.
- The data training bias
What you feed the LLM = the quality of the LLM, so this means that the quality of the training matters. When the training data is bad, there can be a biased data reflection, potentially perpetuating or amplifying societal biases.
Wrap up
Recognizing these limitations helps in using LLMs effectively while considering their strengths and weaknesses. Addressing and minimizing hallucination in LLMs involves ongoing research and development to enhance the model’s contextual understanding, improve fact-checking capabilities, and refine its ability to generate accurate and contextually appropriate responses.




