

How to scrape web data with selenium Selenium
Scrap web data easily with selenium

We can extract a ton of information about consumers, goods, people, stock markets, etc. through web scraping.
One may use the information gathered from a website, such as an e-commerce portal, a job portal, social media channels, and so on, to comprehend the purchasing habits of customers, the attrition patterns of employees, the feelings of customers, and so forth.
Python's most widely used libraries or frameworks for web scraping are BeautifulSoup, Scrappy, and Selenium.
This article will discuss Python Web scraping with Selenium.
Selenium
An open-source web-based automation tool is Selenium. Although web scraping is not Selenium's primary use in the industry. We'll use Google chrome for this article, but you may use any other browser to check it out; it'll work almost exactly the same.
Installation and set-up
We will install the selenium package and the chrome web driver.
pip install selenium #using pip
conda install -c conda-forge selenium #using conda
You can use any of the following techniques to download web drivers:
From the URL below, you may either directly download the Chrome driver.
https://chromedriver.chromium.org/downloads
Alternatively, you may access it directly by using the code-driver below.
webdriver.Chrome(ChromeDriverManager().install())
Importing the required libraries
import io
import os
import time
import requests
from PIL import Image
import selenium
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
Driver installation
driver = webdriver.Chrome(ChromeDriverManager().install())
Add URL you want to scrape
search_url=“https://www.google.com/search?q=cars&sxsrf=ALiCzsa1GYMTLQhI1kpNy0PDELTCyXHp2g:1665325072454&source=lnms&tbm=isch&sa=X&ved=2ahUKEwjo-4Orq9P6AhWjsaQKHWrPBRMQ_AUoAXoECAIQAw&biw=1440&bih=789&dpr=2"
driver.get(search_url.format(q='Car'))
Then, using our variable search_url, we paste the URL into the variable. We use the driver to execute the cell and the get("search word") function. Doing this will open a new browser tab for that URL.
Go to the end of the page
We could use this line of code to go to the page's bottom. After that, we give a 5-second sleep period to ensure that we don't encounter an issue where we try to read content from a page that hasn't yet loaded.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5) #sleep between interactions
Find the pictures that need to be scraped from the page
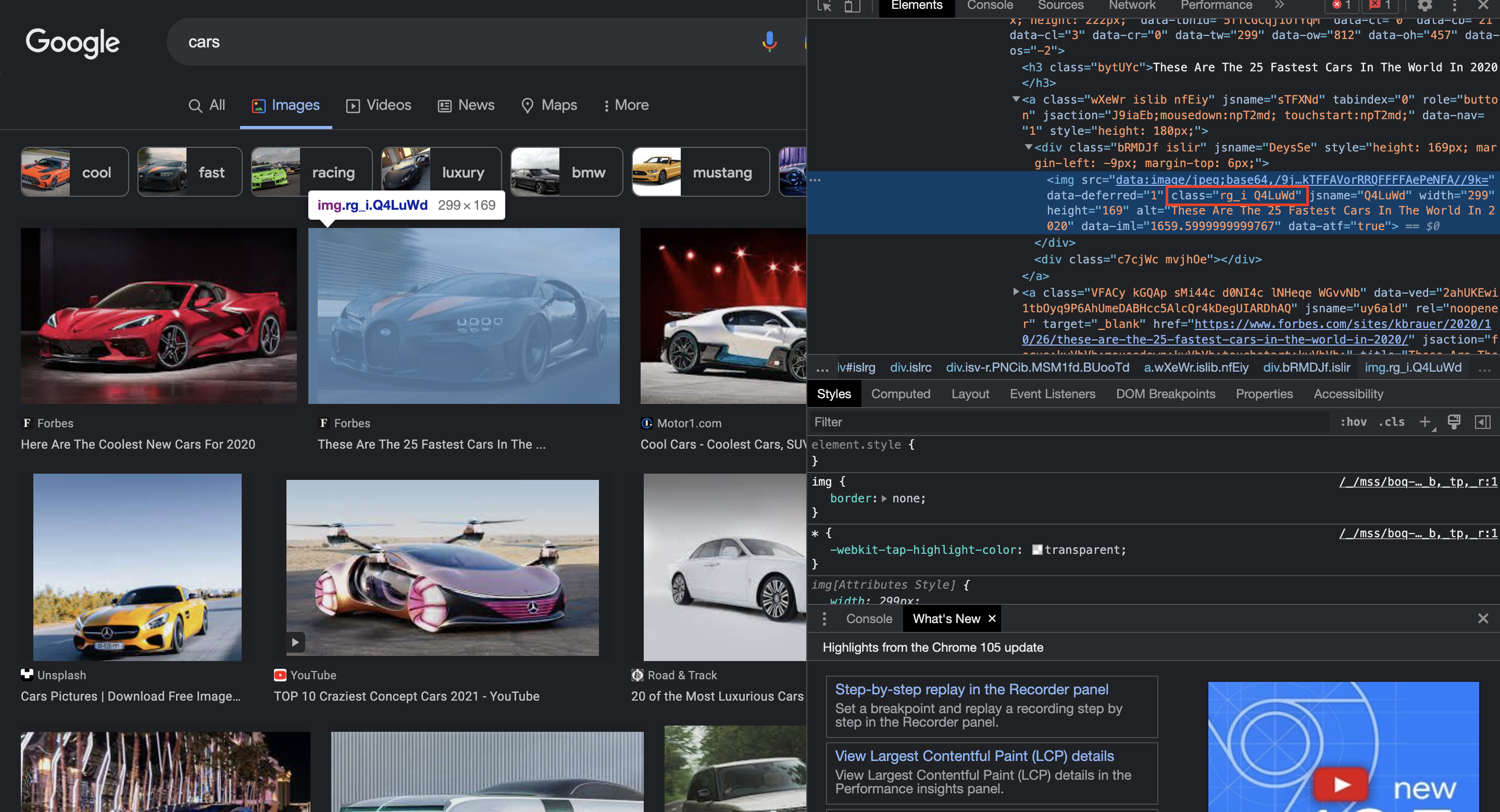
We'll now get every picture link on that specific page. So, to achieve this, open the browser window, right-click anywhere on the page, and choose inspect element, or use Ctrl+Shift+I to activate the developer tools. We will search for a common id, class, etc. among all of the photos; in this instance, class will be used.
imgFind = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
imgageResults=len(imgFind)
Extract each image's corresponding link
As far as we can tell, the photographs that are displayed on the page are still only thumbnails of the larger images. Therefore, in order to download each image, we must click on each thumbnail and gather pertinent data about that particular image.
img_urls = set()
for i in range(0,len(imgageResults)):
img=imgageResults[i]
try:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
except ElementClickInterceptedException or ElementNotInteractableException as err:
print(err)
Basically, what we did above was to go through each thumbnail one at a time, then click it and give our browser a 2 secs sleep. To find the image on the website, we had to search for its specific HTML element. Still, we receive many results for a given picture. But the download URL for that photograph is all that matters to us. So, after extracting the src property from each result for that picture, we check to see if https is included in the src or not. as an online link normally begins with https.
Download and save each image
os.chdir('C:/User/Desktop/')
baseDir=os.getcwd()
for i, url in enumerate(img_urls):
file_name = f"{i:150}.jpg"
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(baseDir, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {url} - {e}")
With this, we have been able to finally extract images from Google into our desktop for whatever project we want to use it for.
Conclusion
We looked at what selenium is, how to use it to scrape photos from a website (we used Google as an example), and how to save the scraped images in a folder in our local computer in this article, so I'm glad you stuck with me to the end.




